余额与计费
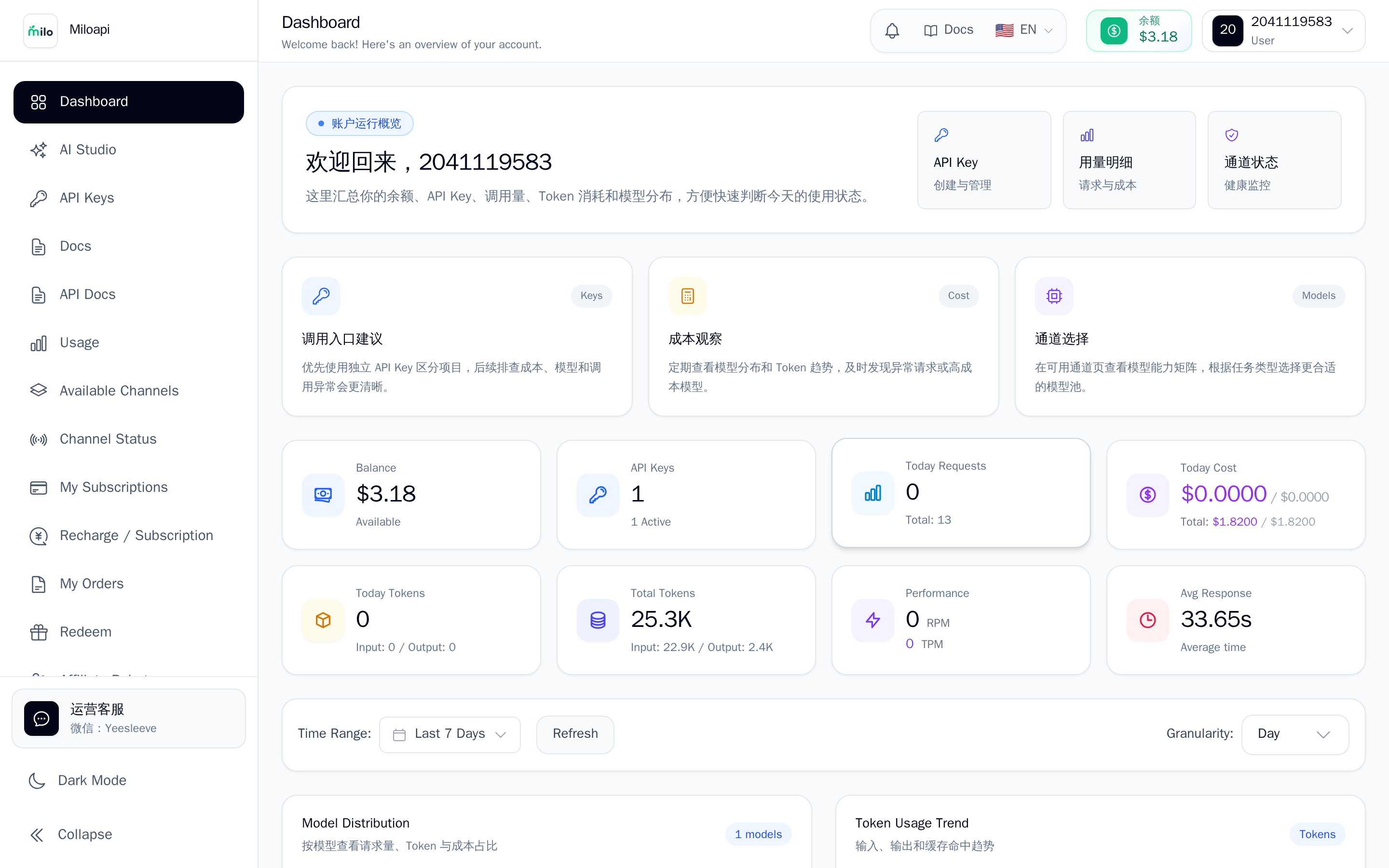
1. 在哪查余额和用量
| 在哪 | 看什么 |
|---|---|
| 顶部 余额胶囊 | 当前余额(美元),实时 |
| 侧栏 仪表盘 | 今日 / 本周 / 本月 用量趋势图 |
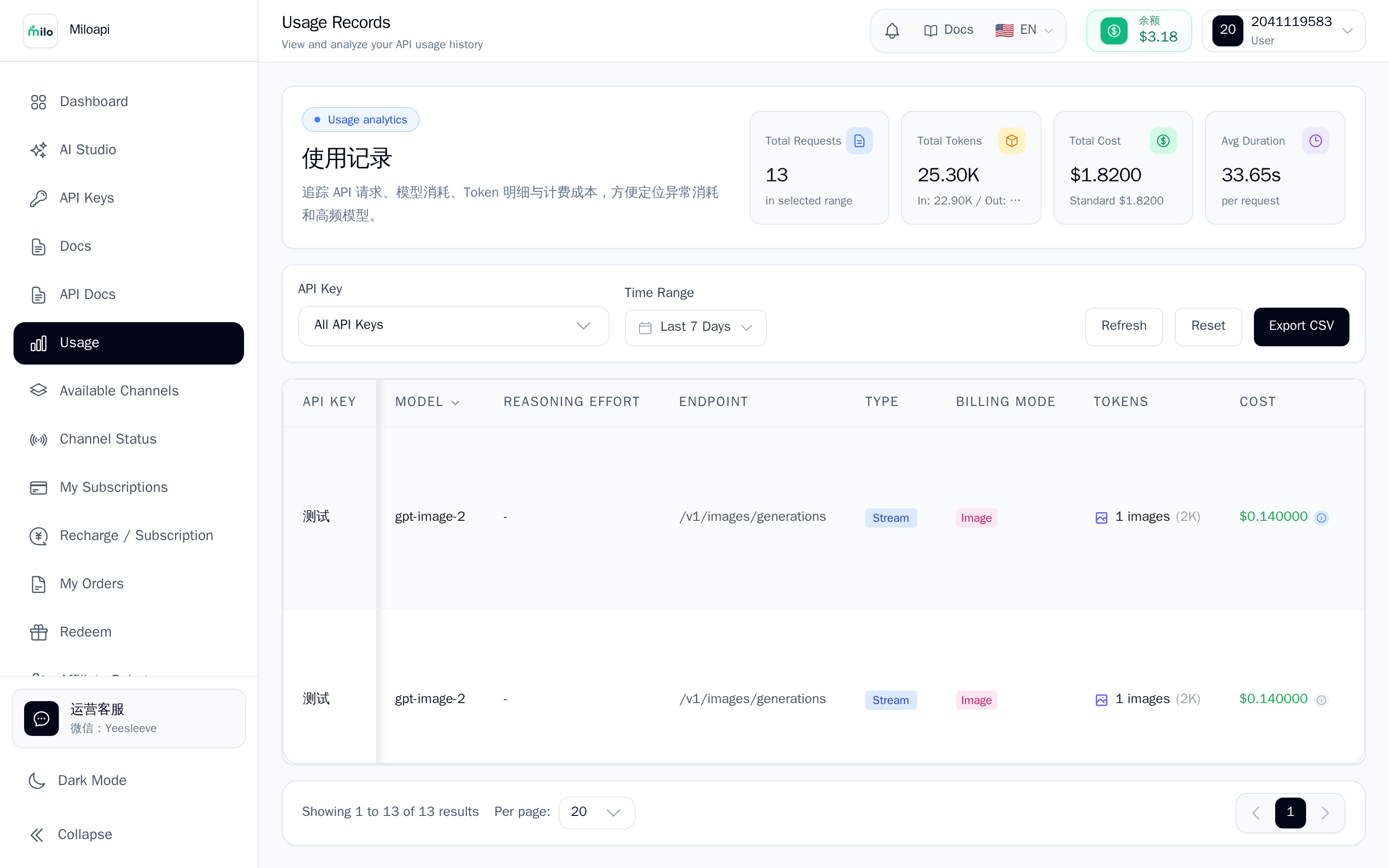
| 侧栏 使用记录 | 每次调用明细:模型、tokens、费用、时间 |
| 侧栏 API 密钥 | 每个 Key 累计花了多少 |
| 侧栏 钱包 | 充值记录 + 余额变动流水 |
📊 数据延迟:大约 5 秒 — 调用完到使用记录出现需要 1-5 秒,刷新即可。
2. 计费公式
本次调用扣款 = (基础 tokens × 模型单价 + 缓存 tokens × 缓存单价) × 分组倍率
基础单价跟着上游官方走(OpenAI / Anthropic / Google),分组倍率取决于你的 Key 所在分组:
| 分组 | 倍率 |
|---|---|
| GPT | 0.30× |
| Claude-MAX 池 | 3.00× |
| gemini | 1.00× |
| gpt(无生图) | 0.15× |
| 反重力 | 1.00× |
3. 生图计费
生图按"张"收费,跟 tokens 无关:
| 尺寸 | 单价(GPT 池) |
|---|---|
| 1024×1024 (1K) | $0.07 / 张 |
| 1024×1536 / 1536×1024 (2K) | $0.14 / 张 |
| 1792×1024 / 1024×1792 (4K) | $0.278 / 张 |
工作台一次生 N 张 = N 次独立调用,所以扣 N 倍。
4. 关于缓存(Claude 专属)
Claude 系列模型支持 Prompt Caching,长 prompt 反复调用时,缓存内容只收 10% 单价。
这对 Claude Code 这种"agent 反复读同一份代码"的场景非常划算,典型能省 60-80% 成本。
| Token 类型 | 倍率 |
|---|---|
| 普通输入 | 1.0×(基准) |
| 缓存写入(5 分钟) | 1.25× |
| 缓存命中读取 | 0.10×(打 1 折) |
| 输出 | 5.0×(基准的 5 倍) |
使用记录里能单独看到 cache_creation_tokens / cache_read_tokens 这两项,反映你的缓存命中情况。
5. 用量明细字段
使用记录每行包含:
| 字段 | 含义 |
|---|---|
| Model | 实际调用的模型(经过映射后) |
| Requested model | 你客户端发的原始模型名 |
| Endpoint | 走的哪个接口(chat / messages / images) |
| Input tokens | 输入 token 数 |
| Output tokens | 输出 token 数 |
| Cache creation | 缓存写入 token |
| Cache read | 缓存命中读取 token |
| Total cost | 基础费用(list price 算出来的) |
| Actual cost | 实际扣款 = total × 倍率 |
| Duration | 耗时(毫秒) |
| First token | 首 token 延迟(流式时) |
6. 限流规则
| 限流维度 | 规则 |
|---|---|
| 分组 RPM | 分组级别每分钟请求数上限,所有用同一分组 Key 的人共用 |
| 余额 | 余额不足直接拒绝 |
| Key 额度 | 单 Key 设置的上限,达到就拒绝 |
| IP 白名单 | Key 限制 IP 时,非白名单 IP 直接拒绝 |
被限流时返回 429 Too Many Requests,网关会自动重试 1-2 次,通常 1-2 秒内自愈。
7. 实时网关失败回退
某个上游节点临时挂掉时,网关会自动 failover 到下一个节点。你的请求不会失败,只会稍微多花一两秒。这个过程对你完全透明。
8. 关于 USD 记账
充值是 CNY → 入账折算成 USD(按当时汇率,约 1 USD ≈ 7.2 CNY)。后续所有调用都从这个 USD 余额扣。
为什么不用 CNY?因为所有上游(OpenAI / Anthropic / Google)都用 USD 计费,中间转换汇率反而引入误差。
9. 退款 / 注销
- 退款:暂未开放自动退款,如有需要联系微信 Yeesleeve 处理(余额无消费 + 合理理由)
- 账号注销:个人中心 → 安全设置 → 注销账号,会清空所有数据(API Key、对话历史、订单记录)。不可撤销。